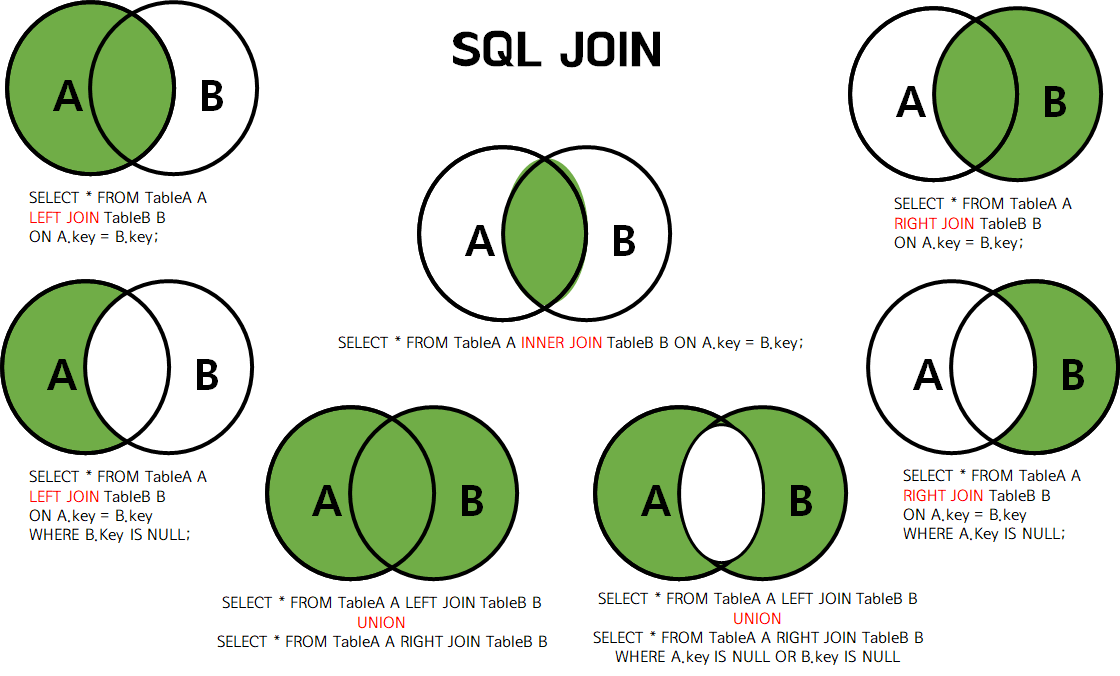
DBMS에서 데이터를 조회할 때 사용하는 JOIN, SUBQUERY, 그리고 UNION을 학습후 정리해본다.
1. JOIN - 테이블을 가로로 연결
행을 기준으로 컬럼을 확장하는 연산
JOIN은 다음 세 가지 기준으로 분류할 수 있다.
- 데이터가 결과에 포함되는가 여부
- JOIN에 사용되는 조건
- 구조적 형태
1-1. 결과 포함 여부 기준
INNER JOIN
- 양쪽 테이블에 모두 존재하는 데이터만
- 가장 기본적이고 가장 많이 사용됨
SELECT *
FROM emp e
JOIN dept d ON e.deptno = d.deptno;
✔ 교집합
✔ JOIN == INNER JOIN
OUTER JOIN
- 매칭되지 않은 데이터도 결과에 포함
LEFT OUTER JOIN
- 왼쪽 테이블은 무조건 유지
- 오른쪽이 없으면 NULL
FROM dept d
LEFT JOIN emp e ON d.deptno = e.deptno;
✔ “사원이 없는 부서도 보고 싶을 때”
RIGHT / FULL OUTER JOIN
- RIGHT는 LEFT로 대체 가능
- FULL은 MySQL 미지원
1-2. 조인 조건 기준
ON 절에서 어떤 비교 연산자를 쓰는가
EQUI JOIN
- 등호(=) 조건
ON e.deptno = d.deptno
✔ 가장 많이 사용되는 형태
NON-EQUI JOIN
- 범위 조건 (<, >, BETWEEN 등)
ON e.sal BETWEEN s.losal AND s.hisal
✔ 급여 등급(SALGRADE) 같은 테이블에서 사용
1-3. 구조적 형태 기준
SELF JOIN
- 자기 자신과 JOIN
- 계층 구조 표현
FROM emp e
JOIN emp m ON e.mgr = m.empno;
CROSS JOIN
- 조건 없는 곱집합
- 거의 사용하지 않음
FROM emp
CROSS JOIN dept;
2. SUBQUERY — 쿼리 안에 쿼리
SUBQUERY = 쿼리를 값처럼 사용하는 방식
SUBQUERY는 “어디에 위치하느냐” 기준으로 3가지로 분류할 수 있다
SELECT field, (SELECT ...) -- 1. 스칼라 서브쿼리(Scalar Subquery)
FROM (SELECT ...) -- 2. 인라인 뷰(Inline View)
WHERE field = (SELECT ...) -- 3. 일반 서브쿼리
2-1. Scalar Subquery (단일 값)
- SELECT 절
- 반드시 하나의 값만 반환
SELECT
ename,
(SELECT dname FROM dept d WHERE d.deptno = e.deptno) AS dname
FROM emp e;
✔ 컬럼처럼 사용
✔ 값 하나만 반환해야 함
2-2. Inline View (FROM 절 서브쿼리)
- FROM 절
- 서브쿼리 결과를 임시 테이블처럼 사용
SELECT *
FROM (
SELECT deptno, AVG(sal) avg_sal
FROM emp
GROUP BY deptno
) t
WHERE avg_sal > 2000;
✔ 복잡한 집계에 자주 사용
2-3. 일반 Subquery (WHERE 절)
- 조건 비교용
- 다중 행 반환 가능
SELECT ename
FROM emp
WHERE sal > (
SELECT sal FROM emp WHERE ename = 'SCOTT'
);
✔ IN, EXISTS, ALL, ANY와 함께 사용
IN - 목록 중 하나라도 같으면
급여 3000 이상인 사람이 속한 부서 의 모든 사원
SELECT e.ename, e.sal
FROM emp e
WHERE e.deptno IN (
SELECT c.deptno FROM emp c WHERE c.sal >= 3000
);
EXISTS - 서브쿼리 결과가 하나라도 있으면 TRUE
이 사원을 매니저로 가지는 부하 직원이 존재하는가?
SELECT m.ename
FROM emp m
WHERE EXISTS (
SELECT 1 FROM emp e WHERE e.mgr = m.empno
);
ALL - 서브쿼리 결과의 모든 값과 비교해서 참
30번 부서 모든 사원보다 급여가 많은 사원
SELECT ename, sal
FROM emp
WHERE sal > ALL (
SELECT sal FROM emp WHERE deptno = 30
);3. UNION / UNION ALL — 결과를 세로로 연결
UNION != JOIN
핵심 차이
- JOIN → 컬럼 증가 (가로)
- UNION → 행 증가 (세로)
3-1. UNION
- 중복 제거 (DISTINCT)
- 성능 비용 있음
SELECT ename FROM emp
UNION
SELECT dname FROM dept;
3-2. UNION ALL
- 중복 제거 ❌
- 빠르고 명확
SELECT ename FROM emp
UNION ALL
SELECT dname FROM dept;
4. 정리
| 상황 | 추천 방식 | 이유 |
| 여러 테이블의 컬럼을 동시에 출력할 때 | JOIN | 서브쿼리는 SELECT 절에 컬럼당 하나씩 써야 해서 비효율적 |
| 단순히 존재 여부만 체크할 때 (EXISTS) | Subquery | 메인 테이블의 중복 방지 및 Early-exit(발견 즉시 종료) 가능 |
| 그룹화(GROUP BY) 후 그 결과와 비교할 때 | Subquery (Inline View) | 집계 데이터를 먼저 확정한 뒤 매칭하는 것이 논리적으로 명확함 |
| 데이터 양이 아주 많을 때 | JOIN | 옵티마이저가 인덱스를 활용한 조인 경로를 더 잘 찾음 |
'Learning Log' 카테고리의 다른 글
| [멋사 클라우드 5기] Day 14 - Modeling, JDBC 이해하기 (1) | 2026.02.09 |
|---|---|
| [멋사 클라우드 5기] Day 13 - DML, DDL, DCL, TCL (0) | 2026.02.08 |
| [멋사 클라우드 5기] Day 11 - DBMS 기초(2), DQL (0) | 2026.02.05 |
| [멋사 클라우드 5기] Day 10 - 객체 다루기, DBMS 기초(1) (0) | 2026.02.04 |
| [멋사 클라우드 5기] Day 9 - Enum 활용, BigNumber, Lombok, 객체 설계 (1) | 2026.02.03 |